VOLLO is optimized for time-series inference of financial AI models.
It supports user-defined models in ONNX or PyTorch comprising layer types such as these.
Additional layer types may be added on request.

VOLLO™ is designed to achieve the lowest latency on financial neural network models, while maximizing throughput, quality and energy- and space-efficiency. Its success has been convincingly demonstrated by its performance in the STAC-ML™ Markets (Inference) benchmarks1 which represent such models.
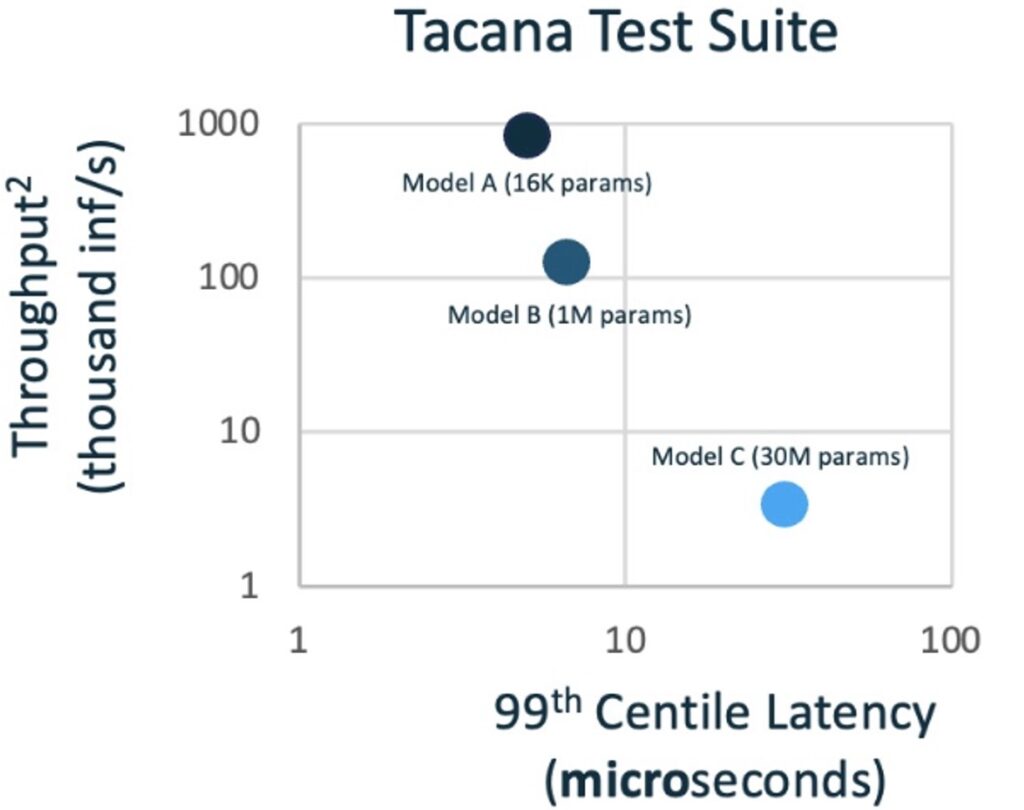
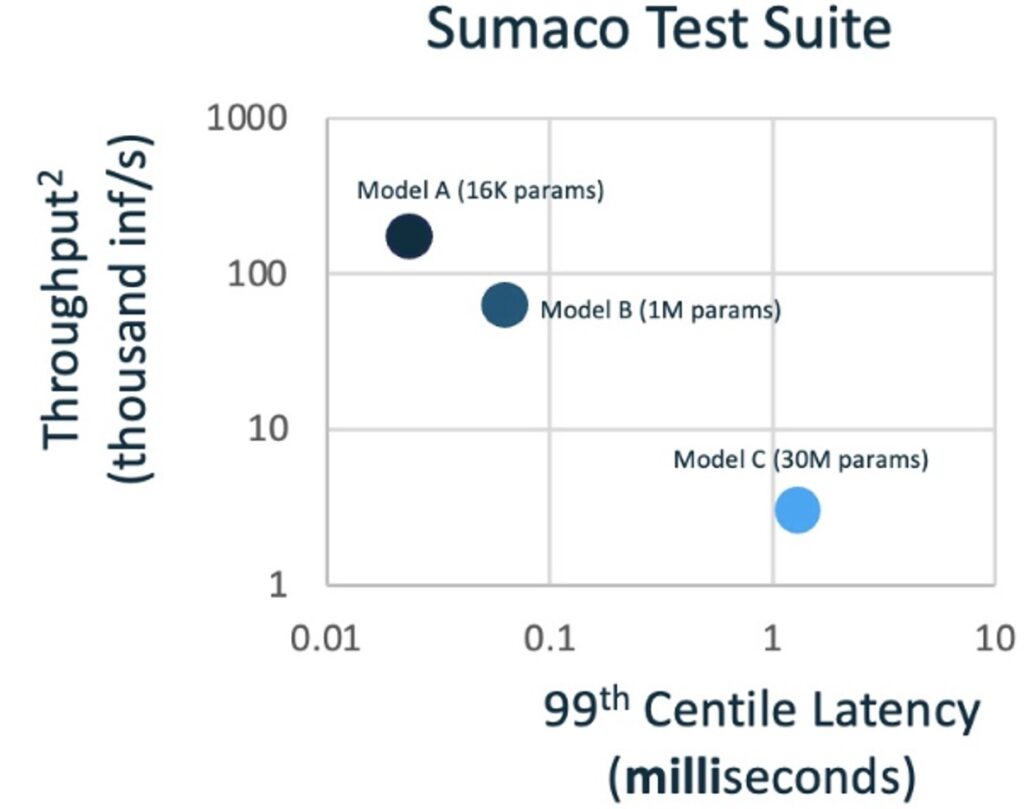
Independently audited results show that VOLLO has less than half the latency of its nearest competitor. Other competitors demonstrated up to 20x longer latencies than VOLLO. Audited latencies as low as 5.1 microseconds were achieved by VOLLO for the neural network models defined in the STAC–ML benchmarks and subsequent improvements have reduced those latencies even further.
Although not audited by STAC, the compute latency (excluding off-chip communications) is of the order of just 1 microsecond. This means VOLLO is fast enough to open up new applications, such as inference in a NIC subsystem.
VOLLO is optimized for time-series inference of financial AI models.
It supports user-defined models in ONNX or PyTorch comprising layer types such as these.
Additional layer types may be added on request.

Evaluate:
Deploy:

Designed to be installed in a server co-located in a stock exchange, VOLLO achieves very high throughput and low energy consumption in a 1U server. This significantly reduces the costs incurred in running co-located servers. Up to four PCIe accelerator cards will run in a 1U server at less than 650W.

Models can be trained in PyTorch or TensorFlow before being exported in ONNX format into the VOLLO tool suite, making it simple to program from your existing ML development environment.

The flexibility of FPGA technology ensures that not only can VOLLO be software-configured with multiple user models today, but significant architectural innovations can also be adopted quickly with optimal compute resources3.
1www.STACresearch.com/MRTL230426
2STAC-ML.Markets.Inf.T.LSTM_A.4.LAT.v1 and STAC-ML.Markets.Inf.T.LSTM_A.4.TPUT.v1
3Myrtle.ai can provide optimized FPGA bitstreams for new and emerging models based on an extensive IP library for AI inference
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation