In this last post of our Vision Transformer series, we show the performance results of 3 different versions of the Vision Transformer model (Base, Small and Tiny) running on various hardware platforms. The objective is to understand which platform gives the best performance, also taking into consideration their power consumption. This is necessary for enabling deployments on systems, such as satellites, which have limited power constraints. For inference on a satellite system, we focus our performance results on embedded low power systems.

Iridium NEXT LEO Satellite ©Thales Alenia Space (Image Courtesy of Thales Alenia Space)
Hardware Platforms
We compare the performance of 3 different hardware platforms.
Quad-Core ARM Cortex. The first platform we compare is the quad-core ARM Cortex on a Raspberry Pi 4, this tiny computer has a quad-core Cortex-A72 (ARM v8) 64-bit CPU. This device doesn’t have a GPU, but nevertheless it is able to efficiently execute a range of tasks using frameworks such as ONNX. The Raspberry Pi 4 also supports the PyArmNN framework, which allows developers to accelerate deep learning workloads through a Python API. We have run some experiments with both PyArmNN and ONNX Runtime, but the latter proved to be more efficient so all results reported here are obtained with ONNX Runtime. The power consumption of the Raspberry Pi is approximately 5W and it provides a good inference baseline for an embedded CPU only system.
NVIDIA Jetson Nano. The second platform is the NVIDIA Jetson Nano, a small and powerful computer with a quad-core ARM A57 CPU. This device also has a 128-core NVIDIA Maxwell architecture-based GPU. The power consumption is in the range 5-10 W, so it is slightly higher than the Raspberry Pi 4. This platform is designed for low power inference applications such as this. In order to run our models on this device we have experimented both with ONNX Runtime and TensorRT. We found that TensorRT didn’t give significant improvement compared to ONNX Runtime so the results reported here are measured using ONNX Runtime.
Kintex KCU Space FPGA. The third platform is the Kintex KCU Space FPGA, which delivers ASIC-class system-level performance with approximately 10W of power consumption, thus similar to the Jetson Nano power. The FPGA is radiation tolerant and so suitable for both Low Earth Orbit and deep space deployments. We investigate this platform to see if it can provide sufficient compute for this kind of inference on a space grade device. The results reported for this platform haven’t been directly measured but have been predicted using a software model. For the Kintex device we are able to effectively deploy our sparsity exploiting MAU Core IP, so we present results for that device for both a fully dense model and for a 50% compressed sparse model. We choose the 50% compression factor as this provides the best accuracy for all three model configurations.
Achieved Throughput for the Vision Tranformer
The first metric that we have used to measure the hardware performance at inference time is throughput. It is measured as the number of frames that the platforms are able to process per second. The results are shown in the following bar chart, where each color corresponds to a different model version, and have been measured using a batch size of 1. Unlike data center cards such as the NVIDIA T4, embedded devices like the Jetson Nano and the Raspberry Pi are relatively well optimised for batch-1 inference, and this allows us to design a system that doesn’t require large frame buffers, more suitable on a small embedded platform.
We deploy quantized models that give the best inference time on each platform. The precision used on the Raspberry Pi 4 and the Kintex FPGA is INT8, which doesn’t significantly affect the model accuracy as shown in the second blog post, whereas we used FP32 on the Jetson Nano. This is because the Jetson Nano doesn’t support fast native INT8 computation [1], thus the inference is actually faster when using the default FP32 format with CUDA on this platform.
We can immediately infer that the Kintex FPGA shows a much greater theoretical throughput than the ones measured on the Raspberry Pi 4 and the Jetson Nano. If we accept a small accuracy loss by sparsifying 50% of the model’s weights, then we could benefit even more from the greater throughput achievable with the Kintex platform.
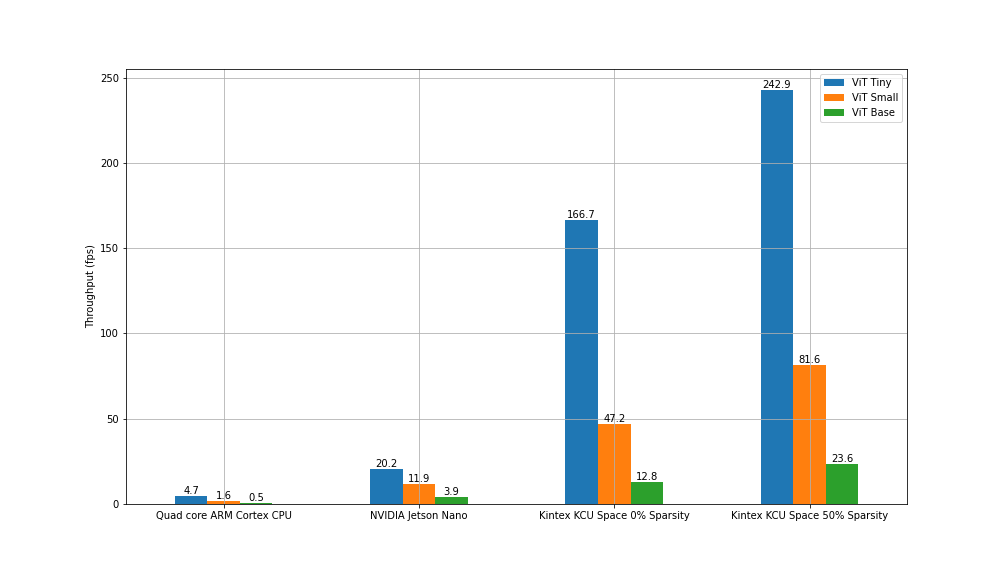
Throughput for Vision Transformers on various platforms
Power Efficiency
Throughput is a metric that only tells us how fast the models can process the input images, but it doesn’t take into account the power consumption required by the hardware devices to run them. This is the reason why it is necessary to look also at other metrics that show the tradeoff between processing capabilities and energy requirements. We have decided to report the throughput/power, a metric measured by dividing the processing frame rate by the power consumption. The results are shown in the following figure. As mentioned before, the precision used on the Raspberry Pi 4 and the Kintex FPGA is INT8 while it was FP32 on the Jetson Nano, and the batch size used for these tests is 1.
The power required to run the devices used to get these results hasn’t been directly measured but it has been taken from their official documentation [2][3][4].
The power of the platforms is very similar, so the Jetson Nano to Kintex comparisons stay the same. The Raspberry Pi advantage is increased as it is lower powered than the other two, but is still lowest overall.
This highlights the power advantage of the Kintex FPGA for space deployments, making it a great platform choice for this type of deployment.
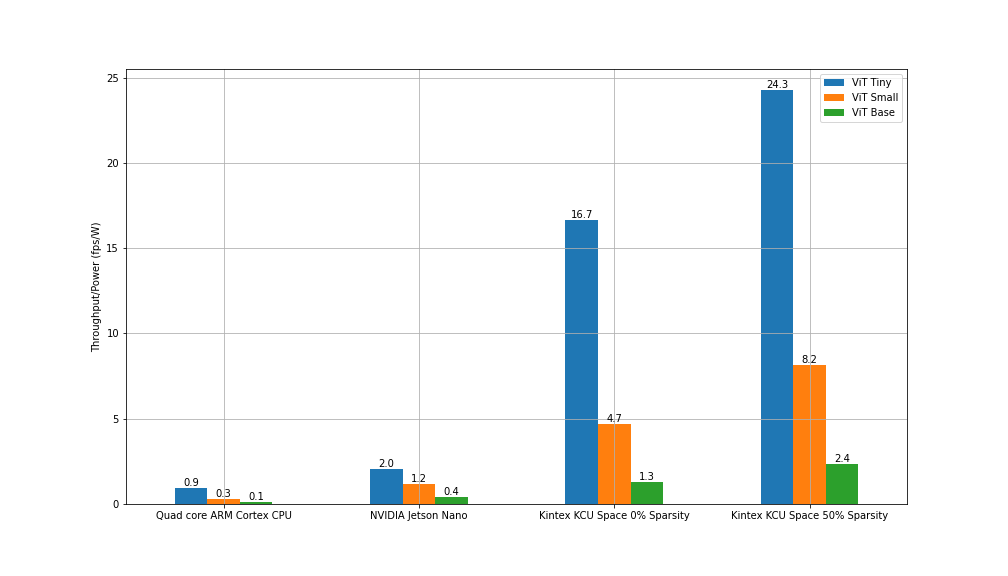
Throughput per Watt for Vision Transformers on various platforms
Conclusion
In this series of blog posts we have explained how we were able to use a transformer-based model for a computer vision application with the goal of deploying it on an actual satellite. We have explained which model compression techniques we have used in order to reduce the memory requirements and the computational complexity of this model. Finally we have compared the performance of various model versions on a range of hardware devices and have demonstrated that the Kintex KCU Space FPGA enables a more power efficient deployment of this type of deep learning models on constrained systems like a satellite, thanks to its low memory requirements and high throughput capabilities.
This work has been done as part of an Innovate UK grant to put AI capabilities on FPGAs in space.
Using configurable space grade FPGAs enables us to keep pace with fast moving algorithm developments in AI. This approach means we can use these very recent transformer models to deliver enhanced image analysis, which will be a central requirement for future space activity. Putting smart, configurable technology closer to the original sensors offers significant savings in the volume of data being downlinked, which is a critical constraint on modern space missions
Roger Ward, CTO at Thales Alenia Space UK
References
[1] https://docs.nvidia.com/deeplearning/tensorrt/support-matrix/index.html#hardware-precision-matrix
[2] Nvidia Jetson Nano Module Data Sheet
[4] Calculated using Xilinx Ultrascale_XPE_2020_1 for XQRKU060 device. 75% Logic, DSP and BRAM usage clocked at 250MHz, plus DDR4 Memory IP. Total power consumption estimate 9.1W.