When we were looking for a great application to run on the Intel Stratix 10 NX FPGA, we turned our attention to WaveNet, a neural network model that we know to be extremely difficult to implement on existing compute platforms, see our previous blog post https://myrtle.ai/learn/wavenet/. Two years on and armed with new AI-optimised FPGA capability – we are able to show a step change in inference performance for this model. Higher throughput at higher audio sampling rates. In this post we describe what we achieved and why this FPGA platform is a good choice for WaveNet.
Why is Real-time WaveNet hard?
WaveNet is fundamentally a hard problem. This speech synthesis vocoder takes acoustic features as input, such as spectrograms generated from text by Tacotron 2 and generates an audio waveform at audio sample rate.

Speech synthesis pipeline using Tacotron 2 and WaveNet
The WaveNet model takes the previous audio output sample as input to the next. In this autoregressive loop, the neural network output is dependent on its previous output, which prevents parallel generation of audio samples. Consequently the entire network must be run in under 62.5us for an audio sampling rate of 16kHz, 41.67us for 24kHz and 31.25us for 32kHz. This means batching must be limited to meet the latency requirement, which in turn reduces achievable throughput on CPU and GPU architectures.
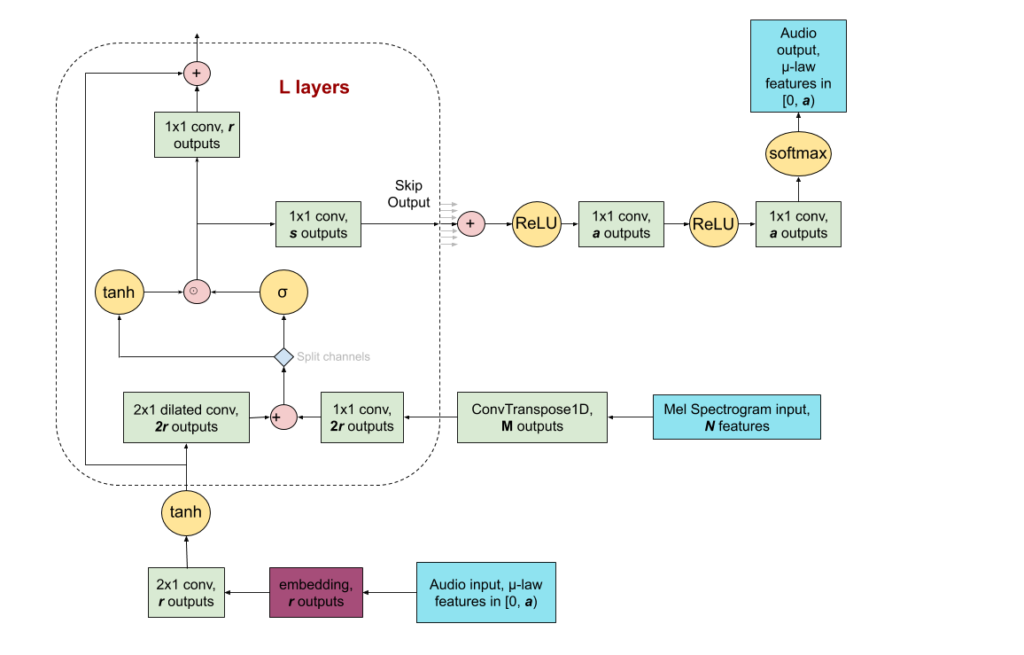
What does the FPGA bring to this problem?
The Intel Stratix 10 NX has brought a raw compute capability to the FPGA much greater than what has been available to date – a 15x headline TOPS improvement over other Stratix 10 FPGAs. That’s compute performance on par with a GPU but on FPGA fabric.
But the challenge with WaveNet is not just about compute performance, it’s about how efficiently that compute can be used. WaveNet is fundamentally a neural network with an extremely low latency bound – and latency is where FPGAs really excel. The FPGA maintains its compute efficiency even in extremely low latency scenarios, down to tens of microseconds in this case. This ability to deliver massive compute performance that remains effective under low latencies is the key to getting the very best performance for this model.
Several features of the FPGA contribute to this. Flexibility in the FPGA fabric itself enables us to move data around the chip to where it needs to be, just in time, without having to deal with things like caches. The WaveNet model is sufficiently small that we can hold the model parameters in on-chip RAM, feeding model parameters to dedicated matrix multiplication circuitry without bandwidth constraints. We pipeline processing through dedicated logic for non-linearities, so that matrix multiply is used to maximum capacity. And for larger stores of data such as that needed to feed dilated convolutions, we use the HBM2 memories, with much higher bandwidths than going to off-chip DRAM.
The number formats offered for native compute in the Intel Stratix 10 NX device make this a very user-friendly device from a machine learning point of view. We handle activations coming into the system in bfloat16 (Brain Floating Point 16), with intermediate compute converted to Block Floating Point 16. That enables an INT-8 level of performance, while keeping dynamic range and offering a much simplified user flow for the device. Models can be trained using floating point and applied to these number formats post training, without significant loss of accuracy. That’s important for removing additional platform-specific training requirements that would otherwise be incurred for using the FPGA or indeed other reduced-precision inference platforms.
What results did we achieve?
Higher throughput and higher frequency
We compared our solution with nv-wavenet, the fastest implementation of WaveNet known to us at the time of writing. The Intel Stratix 10 NX solution outperforms by 8x at 16kHz audio sampling rate and this advantage grows at higher frequencies. As the GPU performance starts to tail off under increasing pressure from the reducing latency bound, the FPGA performance efficiency is maintained.
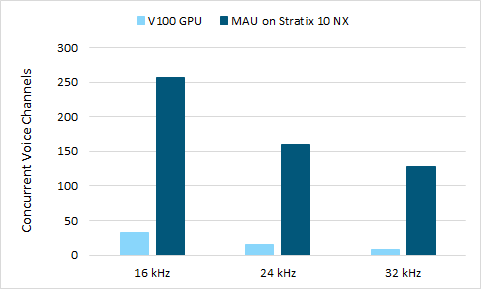
Throughput comparison of FPGA and GPU at alternative audio sampling rates
What does this mean for customers?
Higher audio sampling rates translate to better quality of synthesized speech and better customer experiences. So if you can generate audio at higher frequency, and at the same time save money by processing more concurrent voice streams through the same accelerator then that’s pretty hard to argue with.
You can see the details of our implementation in this whitepaper and see the demo running in this video.
Contact us for more information on how you can access this technology.