Low latency AI inference for
capital markets
Deploy machine learning models that run in microseconds.
Trusted by



World-leading low latency AI inference
Discover how our low latency AI inference products can increase machine learning performance across industries
VOLLO for capital markets
Trade first with microsecond AI inference
Deploy your machine learning models faster than your competitors with VOLLO, the lowest latency inference accelerator. Increase performance and maximize throughput, ensuring you’re never late to trade.
of the latency of our nearest competitor
lower latency than competitors
compute density per server
compute latency
of the latency of our nearest competitor
lower latency than competitors
compute density per server
compute latency
Evaluate
VOLLO
in minutes.
Test your ML model instantly in the VOLLO Sandbox, or use the SDK to evaluate performance locally with no FPGA required.
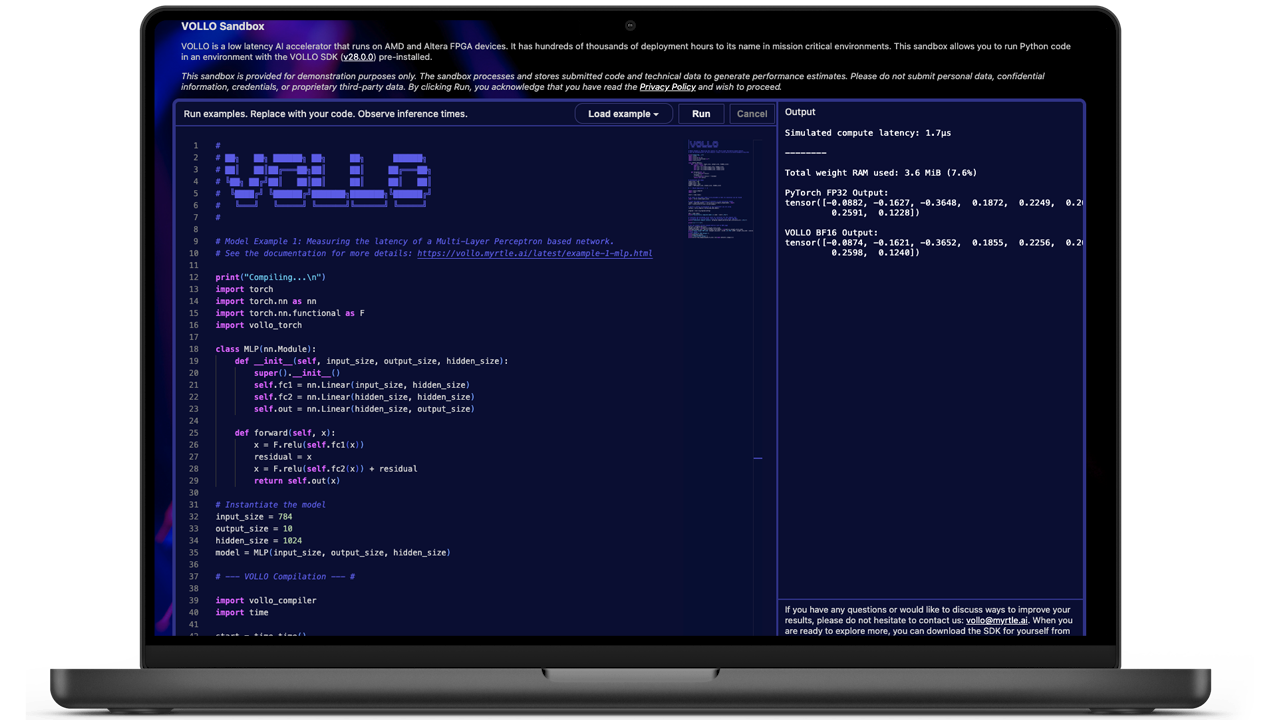
Run an example, test your own model,
and view latency instantly.
Why myrtle.ai?

Expertise you
can rely on
We are a team of hardware/software co-design specialists, infrastructure experts and machine learning scientists – we understand your challenges and can deliver the solutions you need

Trusted partner to
leading companies
We are relied upon by companies at the top of their game because we make it possible for them to deploy complex machine learning models that run in microseconds

Frictionless
deployment
We enable effortless iteration and deployment of machine learning models, freeing engineers to advance development
What our clients say
"We are very happy with VOLLO. We prefer that our competition doesn't know we use it."
Blogs and news
Explore the latest news and insights from the myrtle.ai team


Increase the performance of your machine learning models
Discover how myrtle.ai can help you access low latency inference and deploy complex machine learning models that run in microseconds