At Myrtle.ai, we have been investigating whether Vision Transformers would make a good candidate algorithm for deployment on a Low Earth Orbit (LEO) satellite system. LEO is a commonly used orbit because, unlike GEO (Geostationary Orbit) satellites that must always orbit along Earth’s equator, LEO satellites do not always have to follow a particular path around Earth in the same way since their plane can be tilted. This means there are more available routes at LEO altitudes. Moreover, being near the surface of the Earth allows them to take high resolution images of earth that can be used both for commercial and research purposes.

Iridium® NEXT ©Thales Alenia Space (Image courtesy of Thales Alenia Space)
Deploying compute-intensive algorithms such as AI on power-sensitive systems is a balance between achieving the required algorithm performance and minimizing compute power. The cost of satellite deployment is governed by weight, with power systems being a major contributor. Given the high cost required to send payloads to space, the power budget allocated to each subsystem is very limited and it can go from a few watts to tens or hundreds of watts, depending on the satellite altitude [1].
In this series of posts we describe how we applied compression techniques to transformer-based computer vision models and show how these models perform on a range of low power platforms. This work has been done as part of our LEO research project, funded by Innovate UK.
This first post focuses on the theory behind attention and the application of Vision Transformer models to a satellite image data set.
Transformers in Computer Vision: ViT
In the computer vision domain, convolutional neural networks (CNNs) have been the main players for the last 10 years. The main benefit that differentiated CNNs from other traditional approaches was that they avoided the need for hand-designed visual features, learning instead to perform tasks directly from data “end to end”. Recently, however, researchers have shown that another neural network architecture, the transformer, can be applied to computer vision to achieve results almost on-par with state-of-the-art CNN models, while being more robust to noise and perturbations in images.
The Vision Transformer model (ViT) was first proposed by Google at the end of 2020 and it has highlighted the great benefits of transformer-based models applied in Computer Vision, as we explain in this blog post series.
What makes Transformers interesting – Attention
Central to all transformer models is the attention mechanism.
Human visual attention allows us to focus on a certain region with “high resolution” while perceiving the surrounding regions in “low resolution”. Attention mechanisms in deep learning try to replicate that type of perception by paying more attention to certain parts of an input image or sequence.
One of the first applications to use attention was neural machine translation, a natural language processing (NLP) task which aims to translate a set of words from one language to another. The architectures used for this task were in most cases composed of two main components:
- An encoder that compresses the input information into a representation that is expected to be a good summary of the meaning of the whole source sequence.
- A decoder that takes the compressed information from the encoder and generates an output sequence in the target language.
In the works prior to attention it was common to build a single context vector out of the encoder’s last hidden state, but the problem with this approach is that it becomes difficult to keep long range dependencies since past data tends to be overshadowed by more recent data. Attention adds many connections between the output context vector and the input tokens, so that the result is a richer representation that better handles long range dependencies.
What’s also interesting about attention-based models is that it is possible to visualise the areas where these models pay more attention in order to produce a particular output for a given input sequence. The images below show an example of this type of visualisation, called attention maps. The areas represented with warm colors in the images on the right, correspond to the pixels that were considered more “important” for the correct classification of the input images.

Attention maps for images in the RESISC45 dataset
From Attention to Vision Transformers
The Vision Transformers used for this project are not based on the traditional attention technique but on a different variation known as self-attention.
The main difference is the fact that in self-attention the target sequence is equal to the input sequence. The goal is to relate different positions of a single sequence in order to compute a representation of the same sequence. This technique can be applied for tasks like machine reading, abstractive summarization and image description generation.
Transformers are models entirely built on self-attention that no longer use a sequence-aligned recurrent architecture. The architecture is composed of an encoder and a decoder like in previous sequence-to-sequence models, but in this case the attention weights are calculated using dot-product operations.
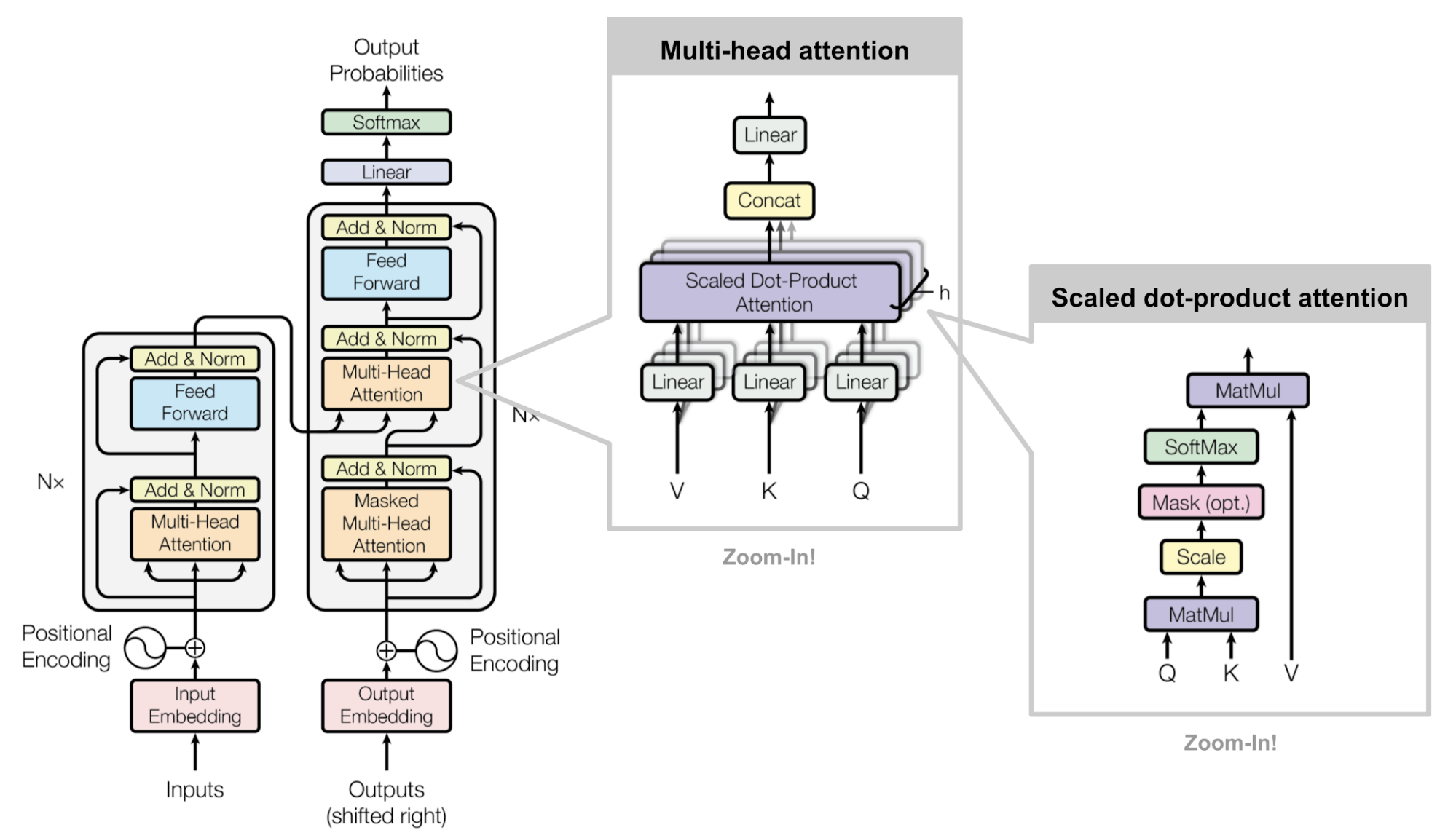
Transformer model architecture (Credits: image from “Attention? Attention!” by Lilian Weng)
The left component is the encoder and the right component is the decoder
The Vision Transformer architecture is mainly composed of a sequence of transformer encoders, like the ones commonly used in transformers for NLP applications. The input and output layers needed to be slightly modified in order to be able to work with images.
The input image is first split into a set of patches. These patches are then flattened and projected into lower-dimensional linear embeddings. It is not possible to just feed the linear embeddings to the next layers because the ViT model doesn’t know a priori anything about the relative location of patches in the image, or even that the image has a 2D structure. This is why it is necessary to add learnable positional embeddings. ViT doesn’t make use of a decoder at the end of the sequence of transformers encoders, but it just adds an extra linear layer (the MLP head) for the final classification.
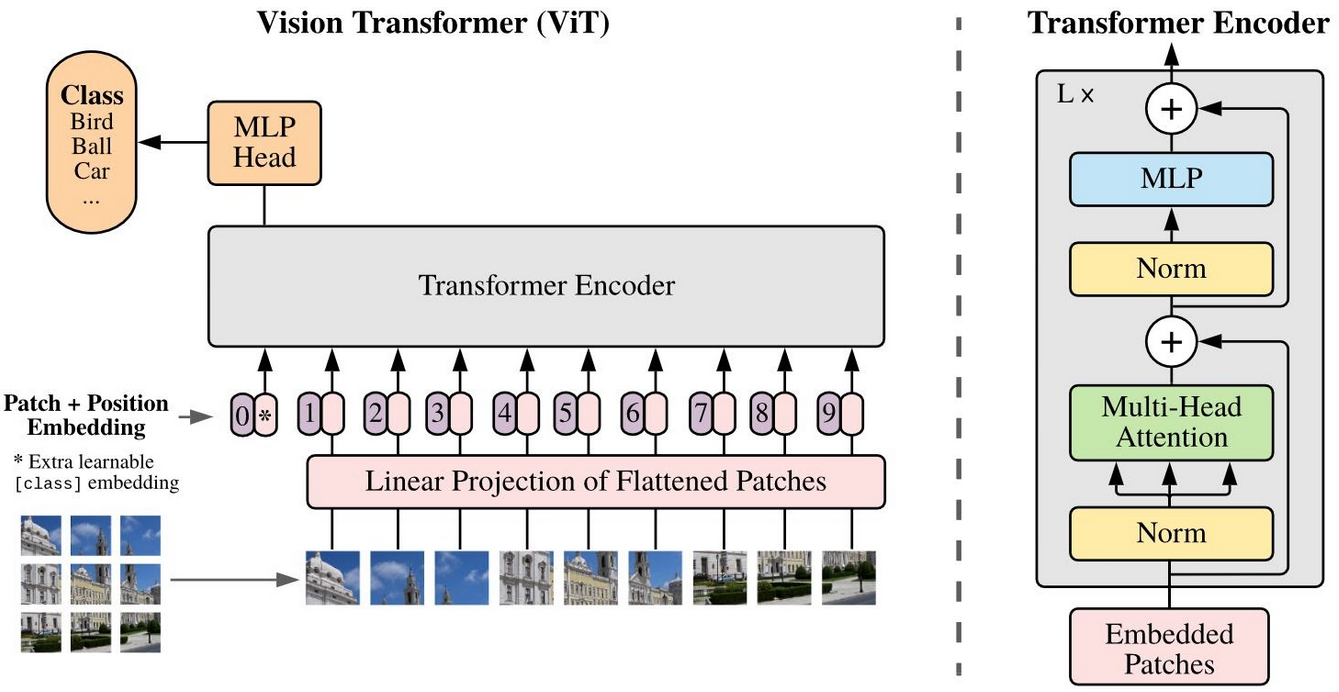
Vision Transformer (Credits: “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale”)
Less Training Data? DeiT is the answer!
The main weakness of ViT is that it needs a massive amount of data to achieve a good accuracy. It actually needs even more data than a CNN because it needs to learn by itself 2D positional information and other image properties that are inherent in the structure of a CNN.
The dataset we use for all our experiments is quite small. In order to overcome this challenge, we used a variation of the ViT model called Data-efficient image Transformer (DeiT) [3], published by Facebook.
DeiT makes use of a better training strategy that exploits a technique called distillation, a process by which one neural network (called “student”) learns from the output of another network (called “teacher”). After training, the student is the model that is going to be used for inference. It has been proven that using a CNN as a teacher model, instead of another transformer-based model, leads to a better student accuracy since the CNN’s architecture has more built in understanding of image structures and it can be pre-trained with a comparatively smaller number of images. The student model can be much smaller than the teacher in terms of number of parameters, so distillation can also be seen as an alternative model compression technique.
The main difference between the ViT learning process and DeiT one is the fact that ViT can only learn from the labels contained in the training dataset, whereas DeiT can learn both from the labelled dataset directly and from a separate teacher model. Learning from the teacher’s predictions means that the model not only learns what the output class should be, but also “how” to make that prediction.
The problem with this method is that it can hamper the resulting accuracy because the student model pursues two different objectives that may be diverging: learning from a labeled dataset (strong supervision) and learning from the teacher. To alleviate this, DeiT adds a distillation token, which is a learned vector that flows through the network along with the transformed image data and is used to compute the distillation loss component.
The only difference in architecture between the DeiT and ViT models is the additional distillation token, thus the number of parameters is almost the same for both models.
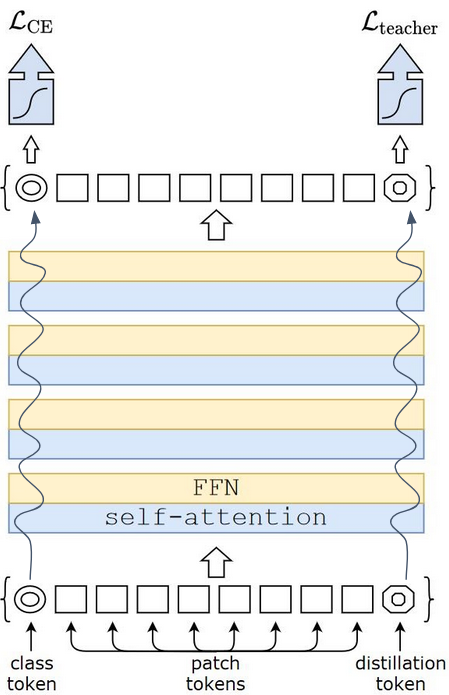
Data-efficient Image Transformer (Credits: image from “Training data-efficient image transformers & distillation through attention”)
Training a Vision Transformer for Low Earth Orbit Satellite
In order to train and test our transformer-based models, we used a dataset called NWPU-RESISC45. It consists of 31,500 remote sensing images divided into 45 scene classes. It has been created by experts in the field of remote sensing image interpretation using images from Google Earth. These images cover more than 100 countries and regions all over the world, thus they contain a wide variety of visual features that a model needs to learn in order to obtain a good accuracy. Each image is 256×256 pixels and they are represented in the red green blue (RGB) color space. The spatial resolution varies from about 30 meters to 0.2 meters per pixel for most of the scene classes except for the classes “island”, “lake”, “mountain” and “snowberg”, which have lower spatial resolutions.
More details about the RESISC45 dataset are provided in [4].

Sample images from RESISC45
We look at the accuracy of the Vision Transformer, Data-efficient Image Transformer and several CNN models when trained for this project on the RESISC45 dataset. This is plotted below as a function of frame rate that is achieved on an NVIDIA T4 GPU. The performance shown for the transformer-based models on this data set is still not as good as the one demonstrated by more traditional CNNs. One reason for this is related to the limited amount of satellite images available during training. In the future this gap can be significantly reduced thanks to many improvements that the research community is currently exploring.
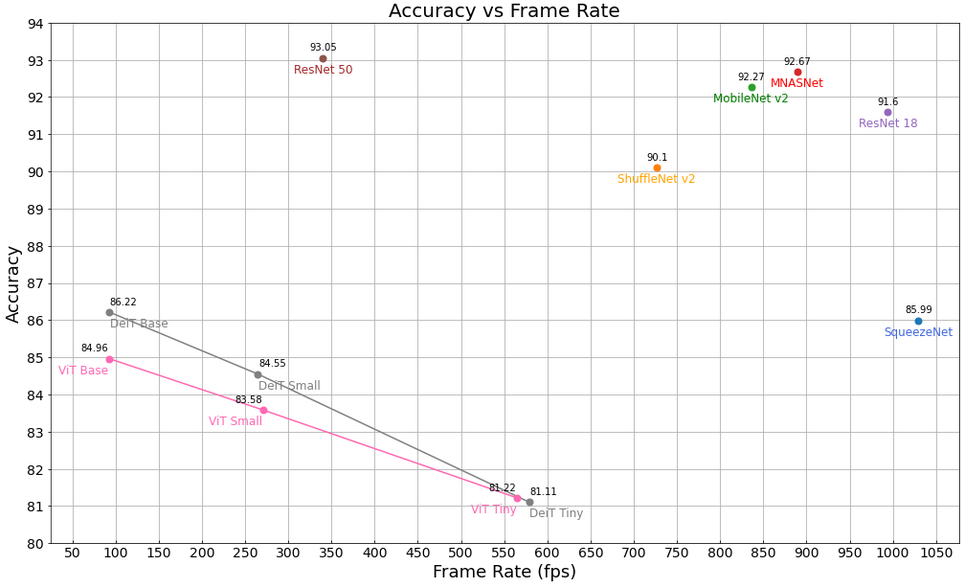
Accuracy vs Frame Rate of CNNs and ViT/DeiT on RESISC45 dataset
A More Robust Algorithm
So why would a Vision Transformer deployment still be advantageous? In a recent paper [5] it has been demonstrated that Vision Transformers are much more robust to severe occlusions, perturbations and domain shifts than traditional CNNs. We have also decided to replicate some of the experiments shown in that paper, and in particular we have run some tests on our DeiT Base and ResNet50 models using the Random PatchDrop technique. The objective of this is to understand how the accuracy of these models changes when you increase the number of image patches that are removed from the original input image.
The two plots below show the results of the test conducted using two different patch sizes, 1×1 and 16×16, thus removing an increasing number of patches with an area of 1 and 256 pixels, respectively.
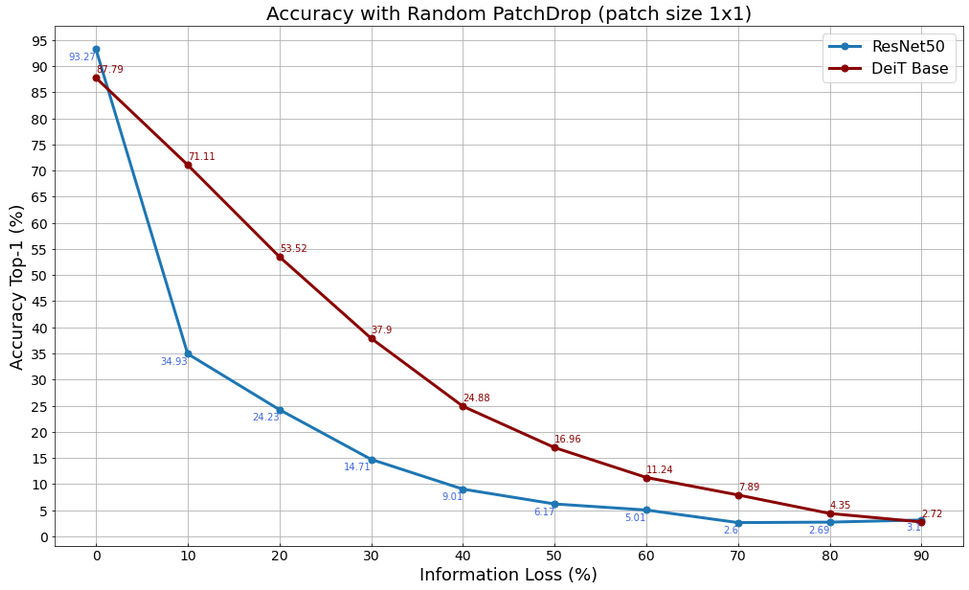
Accuracy vs Proportion of Dropped 1×1 Patches in ResNet/DeiT on RESISC45 dataset
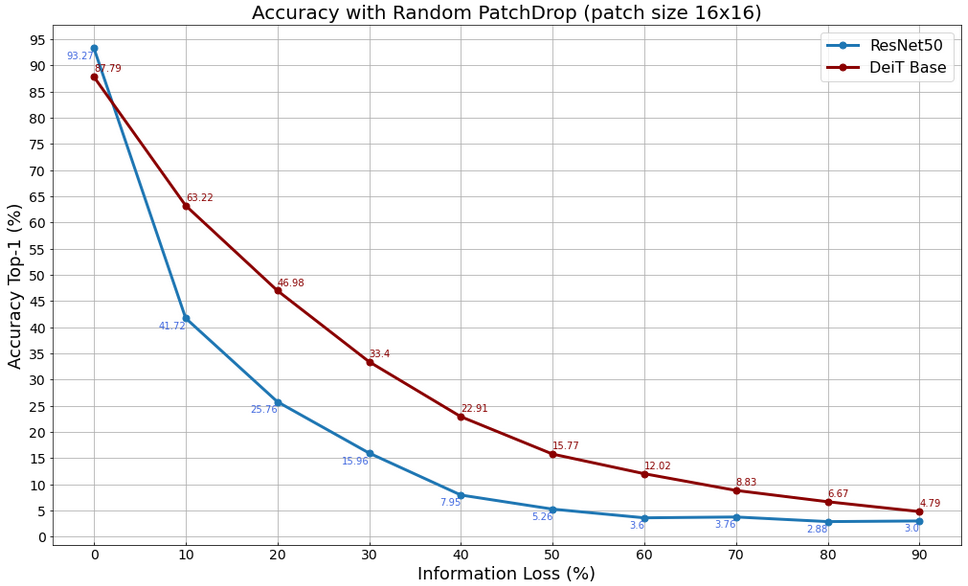
Accuracy vs Proportion of Dropped 16×16 Patches in ResNet/DeiT on RESISC45 dataset
With both models the accuracy significantly drops already when there are 10-20% missing patches, but the ResNet50 accuracy decreases much faster than the DeiT model. Even on our relatively small data set we see that the Vision Transformer provides a more robust algorithm. This could provide an advantage on a LEO satellite AI in the presence of dust, cloud cover and equipment faults.
References
[1] Gavish, B.; Kalvenes, J. The impact of satellite altitude on the performance of LEOS based communication systems.
[2] Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; Uszkoreit, J.; Houlsby, N. An Image Is Worth 16×16 Words: Transformers for Image Recognition At Scale. https://arxiv.org/pdf/2010.11929.pdf
[3] Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. https://arxiv.org/pdf/2012.12877.pdf
[4] Cheng, G.; Han, J.; Lu, X. Remote Sensing Image Scene Classification: Benchmark and State of the Art. https://arxiv.org/pdf/1703.00121.pdf
[5] Naseer, M.; Ranasinghe, K.; Khan, S.; Hayat, M.; Khan, F. S.; Yang, M. Intriguing Properties of Vision Transformers. https://arxiv.org/pdf/2105.10497.pdf